딥시크가 텍스트를 10배 압축하면서도 정확도 97%를 유지하는 OCR 시스템을 공개했다.
이 시스템은 이미지로 텍스트를 처리하는 것이 디지털 텍스트 자체를 처리하는 것보다 컴퓨팅 자원을 덜 사용한다는 아이디어에 기반하며, AI가 메모리 한계 없이 훨씬 긴 문서를 처리할 수 있도록 한다. 시스템은 이미지 처리를 담당하는 딥인코더(DeepEncoder)와 5억7000만 개의 활성 매개변수를 가진 딥시크3B-MoE 기반 텍스트 생성기로 구성되며, 딥인코더는 3억8000만 개의 매개변수로 각 이미지를 분석하고 압축 버전을 생성한다.
딥인코더는 메타의 8000만 매개변수 SAM 모델과 오픈AI의 3억 매개변수 CLIP을 결합하며, 그 사이에 16배 압축기가 이미지 토큰 수를 대폭 줄여 1024x1024 픽셀 이미지를 4096개 토큰에서 256개로 줄인다.
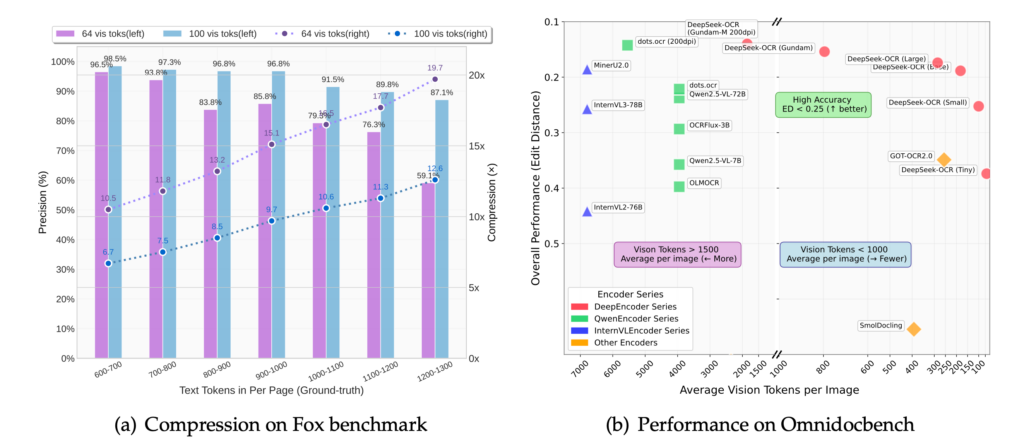
옴니닥벤치(OmniDocBench) 테스트에서 딥시크 OCR은 100개의 비전 토큰만으로 256개를 사용하는 GOT-OCR 2.0을 능가했으며, 800개 미만의 토큰으로 페이지당 6000개 이상의 토큰이 필요한 마이너U 2.0도 앞섰다. 실제 사용에서 딥시크 OCR은 단일 엔비디아 A100 GPU로 하루 20만 페이지 이상을 처리할 수 있으며, 각각 8개의 A100을 탑재한 20개 서버로는 하루 3300만 페이지까지 처리량이 증가한다. 연구진은 약 100개 언어의 3000만 PDF 페이지로 훈련했으며, 코드와 모델 가중치는 모두 공개되어 있다.