알리바바는 자사 최고 수준의 에이전틱 AI 코딩 모델 ‘Qwen3-Coder’를 공개했다고 4일 밝혔다.
알리바바에 따르면 고성능 소프트웨어 개발을 위해 설계된 Qwen3-Coder는 새로운 코드 생성과 복잡한 코딩 워크플로우 관리에서 전체 코드베이스 디버깅에 이르기까지 에이전틱 AI 코딩 작업에서 뛰어난 성능을 발휘한다.
Qwen3-Coder-480B-A35B-Instruct는 MoE(Mixture-of-Experts) 아키텍처 기반의 오픈소스 모델이며, 총 4,800억 개의 파라미터 중 토큰당 350억 개의 파라미터를 활성화해 성능 저하 없이 효율성을 제공한다.
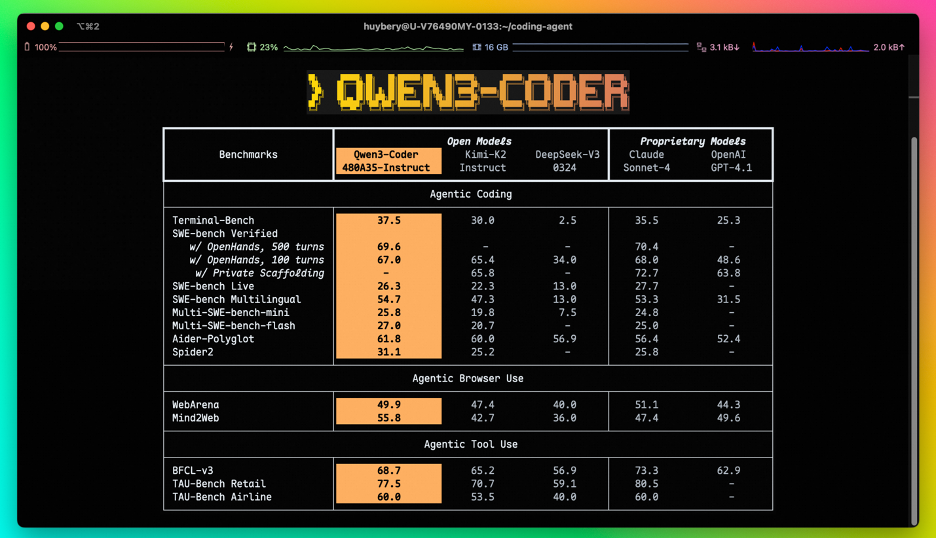
알리바바 측은 “이 모델은 에이전틱 코딩, 브라우저 사용, 툴 사용 등 주요 벤치마크에서 SOTA(state-of-the-art, 최고 성능) 모델들과 견줄 만한 성과를 달성했다”고 강조했다.
또한 알리바바는 개발자가 자연어를 사용해 엔지니어링 작업을 AI에 위임할 수 있게 하는 강력한 명령줄 인터페이스(command-line interface, CLI) 도구인 Qwen Code를 오픈소스로 공개했다. Qwen Code는 맞춤형 프롬프트와 상호작용 프로토콜로 최적화되어, 실제 에이전틱 프로그래밍을 위한 Qwen3-Coder의 역량을 극대화한다. 이 모델은 클로드 코드(Claude Code) 인터페이스와의 연동도 지원해 개발자들이 코딩 작업을 더욱 쉽게 실행할 수 있게 한다.
이어 알리바바 측은 “Qwen3-Coder는 광범위한 코드 및 일반 텍스트 데이터로 학습되어, 강력한 에이전틱 코딩 성능을 구현하도록 설계됐다”며 “기본적으로 25만6천 토큰의 컨텍스트 윈도우를 지원하며, 최대 100만 토큰까지 확장 가능해 단일 세션 내에서 방대한 코드베이스를 처리할 수 있다”고 강조했다.
또한 성능과 관련해 알리바바 측은 “학습 단계에서 토큰 수, 컨텍스트 길이, 합성 데이터의 규모를 확장한 것뿐만 아니라, 후속 학습 과정에서 장기 강화학습(agent RL)과 같은 혁신적인 기법을 적용한 덕분”이라며 “이와 같은 개선을 통해 모델은 외부 도구와의 다단계 상호작용을 통해 복잡한 실제 상황의 문제를 해결할 수 있게 됐다”고 설명했다.
그 결과 Qwen3-Coder는 테스트 타임이나 추론 확장(inference scaling) 없이도 실제 소프트웨어 문제 해결을 위한 AI 모델 능력을 평가하는 벤치마크인 SWE-벤치 베리파이드(SWE-Bench Verified)에서 오픈소스 모델 중 SOTA 성능을 달성했다.
Qwen3-Coder-480B-A35B-Instruct 모델은 현재 허깅 페이스(Hugging Face)와 깃허브(GitHub)에서 이용할 수 있다. 개발자들은 Qwen 챗(Qwen Chat) 또는 알리바바의 생성형 AI 개발 플랫폼인 모델 스튜디오(Model Studio)를 통해 비용 효율적인 API를 이용해 모델을 활용할 수 있다.