정부가 2017년부터 쌓아온 인공지능(AI) 학습용 데이터 170종, 4억 8000만건을 '인공지능 허브'를 통해 민간에 개방한다.
인공지능 허브를 통해 개방되는 AI 학습용 데이터는 비용과 인력 확보 등의 문제로 데이터를 직접 구축하기 어려운 중소기업 및 스타트업, 그리고 대기업도 자체 확보가 어려운 대규모 데이터를 제공하여 국내 AI 산업계의 가장 큰 걸림돌이었던 '데이터 갈증'에 큰 역할을 할 것으로 내다보고 있다.
이번에 공개된 데이터는 기획 단계부터 전문가, 민간 기업은 물론 서울대학교, 한국과학기술원 등 주요 대학과 서울대학교병원, 아산병원 등 병원을 포함한 총 621개 기업·기관이 대거 참여했다. 중심이 된 것은 한국어 음성 데이터, 국내 도로주행 영상 데이터, 주요 암질환 영상 데이터 등 민간에서 대규모로 구축하기 어렵고 구축 시 파급효과가 큰 데이터다.
이와 더불어 데이터 수집, 가공 등 구축 과정에서 국민 누구나 참여할 수 있는 크라우드소싱 방식을 도입해 경력단절 여성, 취업 준비 청년, 퇴직자 등을 포함한 약 4만여 명의 국민 참여를 이끌어 냈다는 점도 주목되고 있다. 이렇게 모인 AI 학습용 데이터는 네이버, LG, 삼성전자, KT, 현대차 등 대기업을 비롯해 스타트업, 대학, 연구기관 등 20여 개 기업/기관이 참여해 활용성 검토를 진행했다.
최근까지 국내 관련 기업들은 그간 인공지능 개발에 필요한 데이터를 확보하기 위해 해외 오픈 데이터에 많이 의존해왔었다. 그러나 한국어, 도로환경 등 국내 실정을 반영하지 못한 해외 데이터는 국내 서비스 개발에 활용 하는데 한계가 있었다.
하지만 인공지능 허브를 통해 개방되는 인공지능 학습용 데이터는 스타트업 등 기업들이 비용과 인력 확보 등의 문제로 직접 구축하거나 자체적으로 확보하기 어려운 대규모 데이터를 제공한다는 점에서 그동안 국내 인공지능 산업계에서 가장 큰 걸림돌로 지적된 ‘데이터 갈증’을 해소하는데 기여할 것으로 전망된다.
체감형 인공지능 서비스 개발 가속화 될 듯
인공지능 허브를 통해 개방된 학습용 데이터는 지역별 방언을 포함한 한국어, 국내 주요 도로와 국내 환자 의료 영상 데이터 등 ‘한국형 인공지능 학습용 데이터’가 대폭 확충되어, 국내 환경에 더욱 적합하고 국민이 체감할 수 있는 인공지능 서비스 개발을 가속화할 것으로 기대된다.
특히 자율주행 데이터는 국내 도로주행 영상뿐만 아니라, 주차 장애물·이동체 인지 영상, 버스 노선 주행 영상 등 국
내 도로 사정을 담은 다채로운 데이터를 제공하여, 국내 자율주행차의 기술 개발에 크게 기여할 것으로 예상된다.
아울러 분야별 전문가와 전문기관, 활용 기업 등은 대규모로 개방되는 인공지능 학습용 데이터의 지속적인 품질관리를 위해 힘을 모았다.
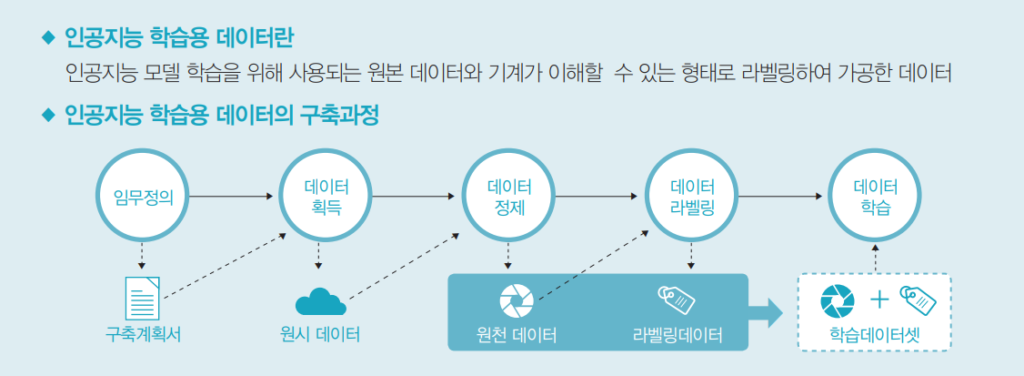
2020년 9월 출범한 ‘인공지능 학습용 데이터 품질자문위원회’와 ‘품질자문단’을 통해서다. 특히 인공지능 전문가로 구성된 품질자문단은 전문 컨설팅을 통해 향후 개방될 데이터들의 구축 계획 타당성, 단계별 품질 관리 절차, 원천 데이터와 라벨링 데이터의 품질·활용도 등을 지속적으로 관리하고 검증해 나갈 계획이다.
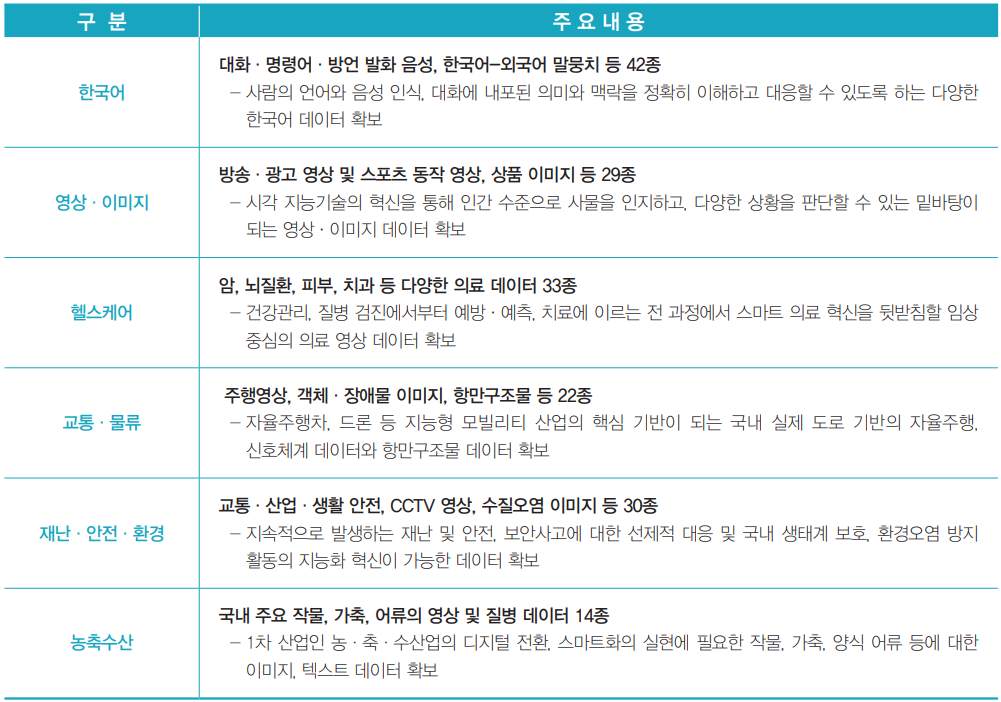
또한 지난해 ‘한국어’, ‘영상·이미지’ 등의 기반 기술 분야와 ‘헬스케어’, ‘교통·물류’, ‘재난·안전·환경’, ‘농축수산’ 등
의 전략 분야로 구축된 총 6대 분야 190종의 데이터가 올해 상반기에 인공지능 허브를 통해 개방될 예정이다.
구축된 데이터를 모아둔 인공지능 허브 또한 서비스 고도화를 위한 준비를 하고 있다. 자동차, 사람과 같은 객체 단위로 데이터를 검색하고 내려받는 기능을 추가하고 데이터 사용 목적별 정보를 제공하여 데이터의 활용도를 높일 계획이다.
정부의 디지털 뉴딜의 핵심인 데이터 댐 사업의 일환으로 추진되는 인공지능 학습용 데이터 구축 사업은 전 산업 분야의 디지털 전환을 가속화하는데 기여하고 있다. 디지털 뉴딜 정책 추진의 2년 차를 맞이한 시점에서 인공지능 학습용 데이터 활용 성과가 산업 곳곳에서 창출되고 있다.
이에 정부는 2025년까지 1,300여 종의 인공지능 학습용 데이터를 구축하는 것을 목표로 하며 "고품질의 인공지능 학습용 데이터를 지속적으로 제공해 누구나 데이터를 쉽게 활용하고, 성과를 공유할 수 있는 환경을 조성하는 데 지원을 아끼지 않겠다"라고 밝힌 바 있다.
향후 구축될 양질의 인공지능 학습용 데이터로 혁신적인 서비스가 창출되고 새로운 데이터가 모이면서 데이터 선순환 생태계가 마련되어 "댐의 물이 대지 곳곳으로 스며들어 꽃을 피우듯이, 이번에 공개되는 데이터들이 산업 곳곳에 널리 활용돼" 대한민국이 글로벌 시장에서 인공지능 선도국가가 되길 바란다.


















소셜댓글